
New Advancements in Surgical Instrument-Action-Target Triplet Recognition
Date:14-09-2023 | 【Print】 【close】
A research group led by Prof. JIA Fucang from the Shenzhen Institute of Advanced Technology (SIAT) of the Chinese Academy of Sciences proposed a multi-task fine-grained spatiotemporal model that effectively identifies action triplets in laparoscopic gallbladder removal surgery videos, achieving state-of-the-art performance.
The study was published in IEEE Journal of Biomedical and Health Informatics on Jul. 27.
In laparoscopic surgery videos, a single frame may contain multiple triplets composed of <surgical instruments, surgical actions, surgical targets>, such as <grasper, grasping, gallbladder>, <hook, dissecting, gallbladder>. These triplets exhibit temporal dependencies and high similarity within different categories, posing a significant challenge to the recognition by deep learning models.
In the context of surgical action triplets, there exists a high similarity within each subcategory of tasks. Taking surgical instruments as an example, the recognition of these instruments relies on a comprehensive analysis of both the instrument's head and handle. Some instruments have similar-looking heads, while other instruments may share a common gray-black handle. Furthermore, the recognition of surgical actions requires considering the contextual content within a video segment.
In this study, the researchers developed a novel model for surgical action triplet recognition. This model consists of two key components: a framework capable of handling multiple tasks simultaneously in surgical video, and a loss function designed for multiple similar labels. Both spatial and temporal features within surgical videos are considered by our framework, a departure from previous methods that predominantly focused on spatial features alone.
The model was submitted to the CholecTriplet2021 challenge organized by the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI). The proposed model outperformed existing methods, including Triplet, Attention Triplet, and Rendezvous approaches. Compared to the state-of-the-art Rendezvous method, the model achieved average precision improvements of 4.6%, 4.0%, and 7.8% in instrument, action, and organ recognition tasks, reaching 82.1%, 51.5%, and 45.5%, respectively. In the overall triplets’ recognition task, the proposed model also improved by 3.1% in average precision, reaching 35.8%. They further demonstrated the effectiveness of different modules through ablation experiments.
"In future work, we aim to enhance recognition accuracy based on the proposed model framework," said Prof. JIA.
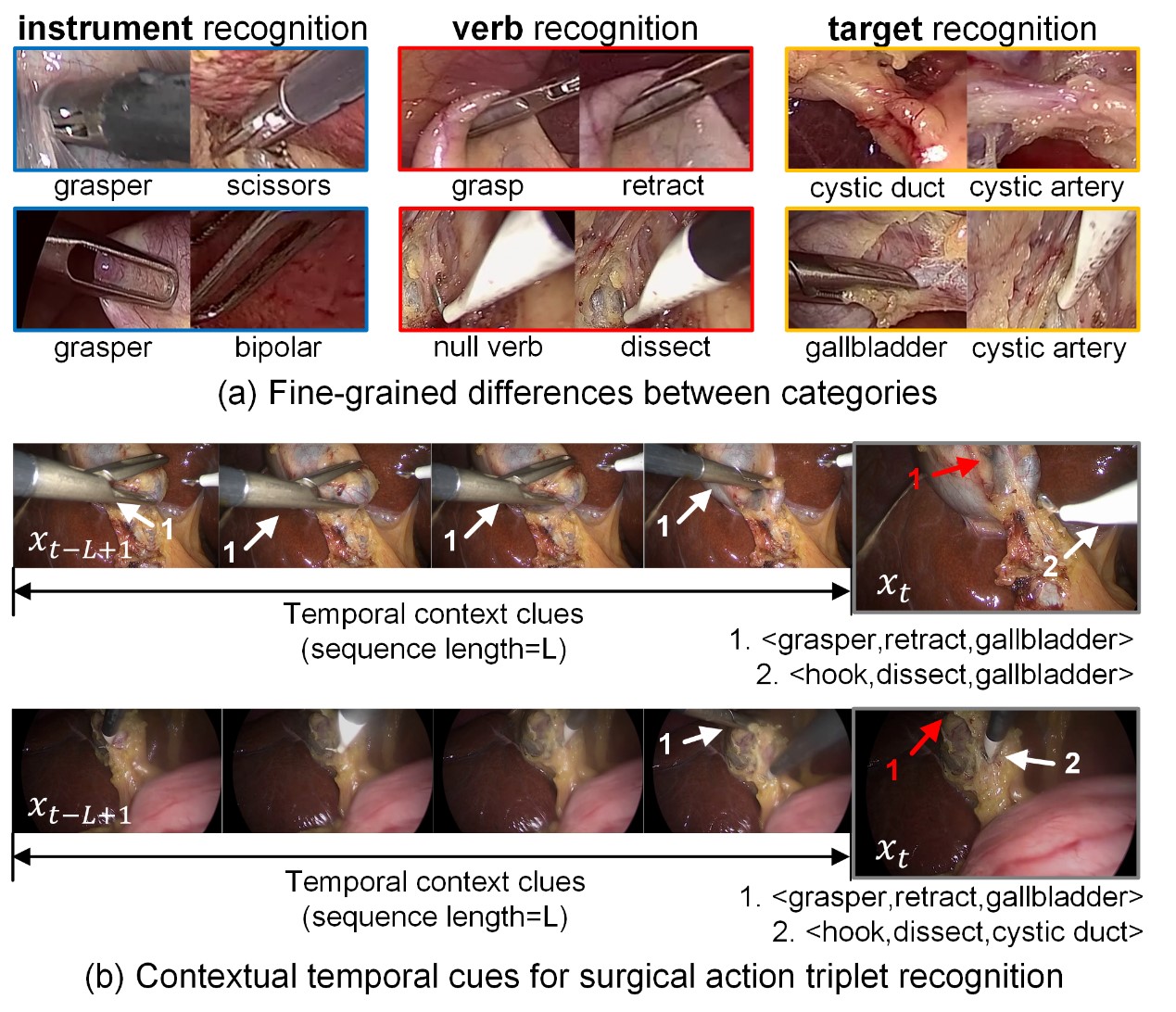
Figure 1. Two characteristics of surgical action triplet recognition. (a) Surgical action triplets consist of three tasks: surgical instruments, surgical actions, and surgical targets. Subcategories within each task share similar visual features. (b) Temporal context plays an important role in triplet recognition. (Image by SIAT)
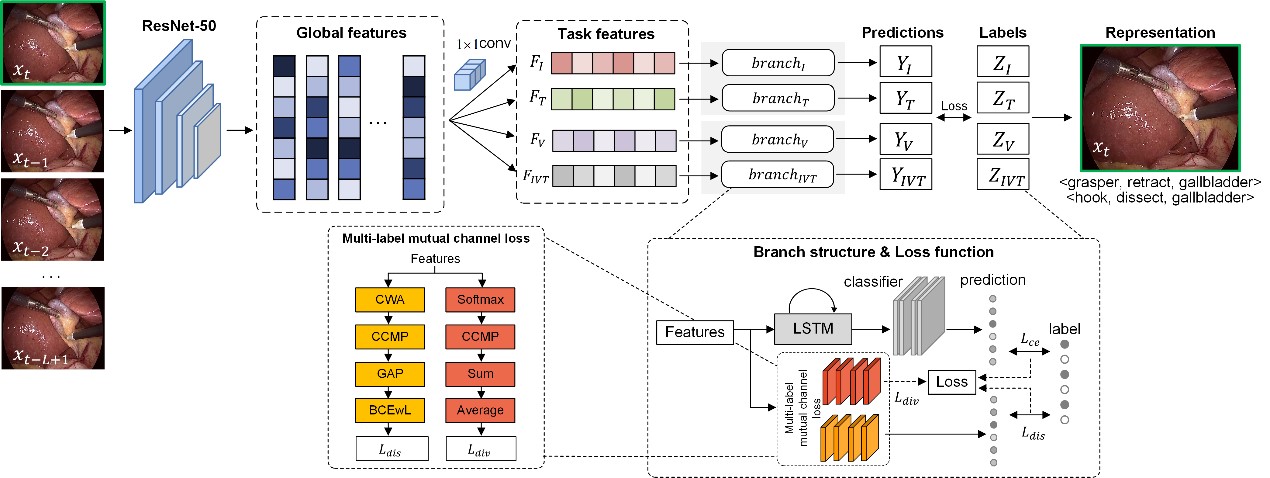
Figure 2. Proposed multi-task fine-grained spatiotemporal network. (Image by SIAT)
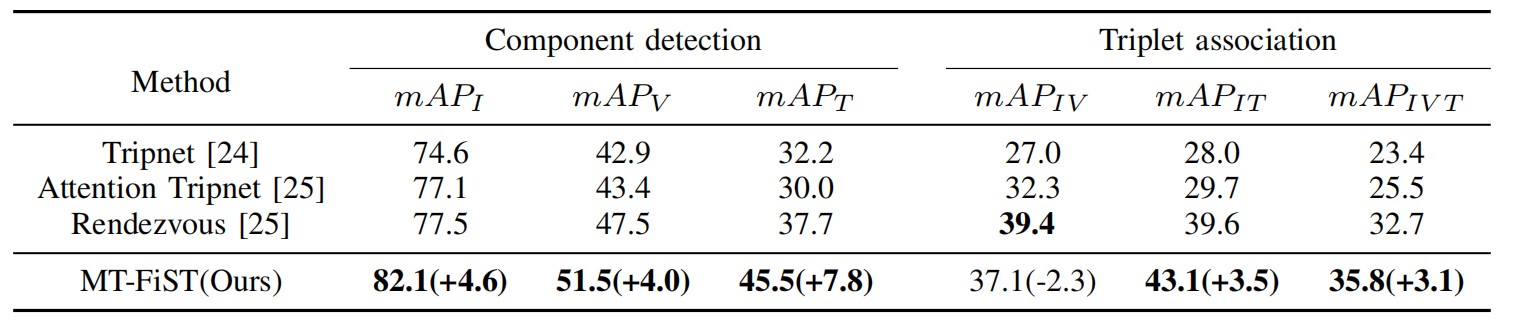
Figure 3. Comparison of triplet recognition results in the CholecTriplet2021 Challenge. (Image by SIAT)
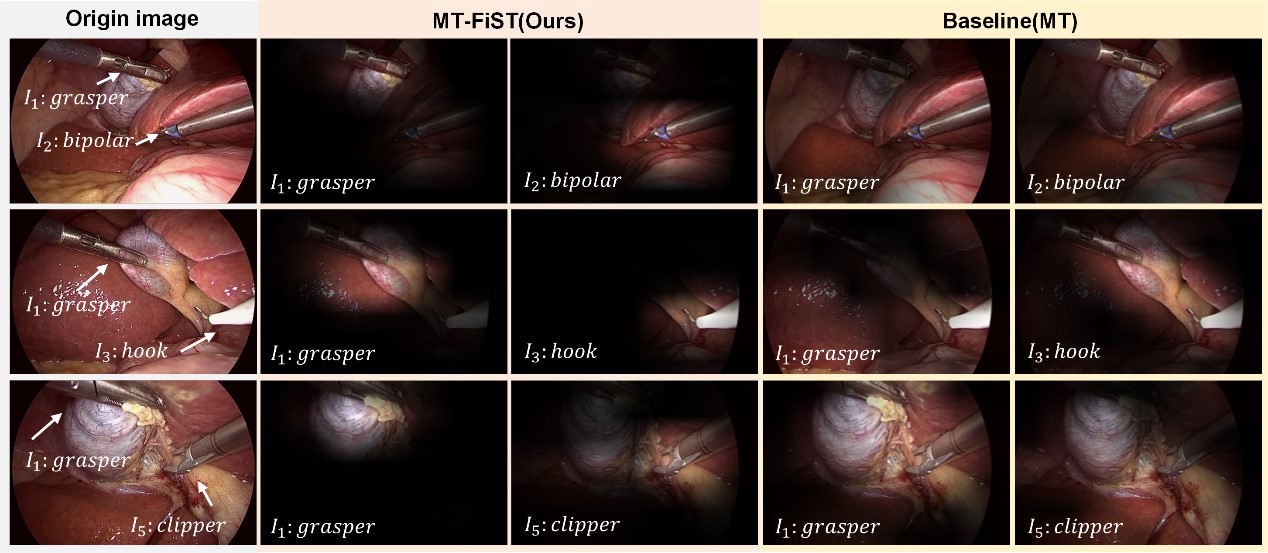
Figure 4. Visualization of attention maps for typical instruments. (Image by SIAT)
Media Contact:
ZHANG Xiaomin
Email:xm.zhang@siat.ac.cn

